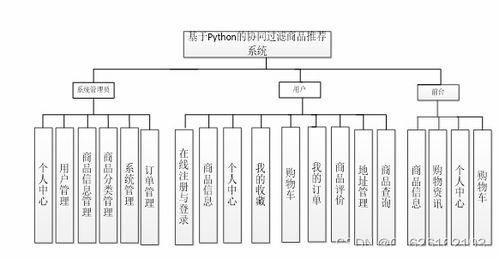
隨著電子商務(wù)的蓬勃發(fā)展和用戶數(shù)據(jù)的爆炸式增長(zhǎng),個(gè)性化推薦系統(tǒng)已成為提升用戶體驗(yàn)、增加商業(yè)轉(zhuǎn)化率的關(guān)鍵技術(shù)。其中,協(xié)同過濾算法因其不依賴商品內(nèi)容、僅通過用戶行為數(shù)據(jù)挖掘相似性而廣受歡迎。本文旨在探討基于Python語(yǔ)言設(shè)計(jì)與實(shí)現(xiàn)一個(gè)協(xié)同過濾商品推薦系統(tǒng),并闡述其在計(jì)算機(jī)網(wǎng)絡(luò)系統(tǒng)工程服務(wù)中的整合與應(yīng)用。
一、 系統(tǒng)核心:協(xié)同過濾算法原理與Python實(shí)現(xiàn)
協(xié)同過濾主要分為兩類:基于用戶的協(xié)同過濾和基于物品的協(xié)同過濾。
- 基于用戶的協(xié)同過濾 (User-Based CF): 核心思想是“興趣相投”。系統(tǒng)通過計(jì)算用戶之間的相似度(如余弦相似度、皮爾遜相關(guān)系數(shù)),找到與目標(biāo)用戶最相似的“鄰居”用戶,然后將鄰居用戶喜歡而目標(biāo)用戶未接觸過的商品推薦給目標(biāo)用戶。
- 基于物品的協(xié)同過濾 (Item-Based CF): 核心思想是“物以類聚”。系統(tǒng)計(jì)算物品之間的相似度,當(dāng)用戶喜歡一個(gè)物品時(shí),系統(tǒng)會(huì)推薦與該物品最相似的其他物品。這種方法通常更穩(wěn)定,計(jì)算效率也更高。
Python實(shí)現(xiàn)關(guān)鍵步驟:
- 數(shù)據(jù)準(zhǔn)備: 使用Pandas庫(kù)加載和處理用戶-物品評(píng)分矩陣(顯式反饋)或行為矩陣(隱式反饋)。
- 相似度計(jì)算: 利用SciPy或NumPy庫(kù)高效計(jì)算用戶或物品間的相似度矩陣。
- 評(píng)分預(yù)測(cè)與推薦生成: 根據(jù)相似度加權(quán)計(jì)算目標(biāo)用戶對(duì)未評(píng)分物品的預(yù)測(cè)評(píng)分,并排序生成Top-N推薦列表。
- 評(píng)估與優(yōu)化: 使用交叉驗(yàn)證、均方根誤差(RMSE)、準(zhǔn)確率/召回率等指標(biāo)評(píng)估模型性能,并可通過矩陣分解(如使用Surprise庫(kù)實(shí)現(xiàn)SVD)解決數(shù)據(jù)稀疏性和冷啟動(dòng)問題。
二、 系統(tǒng)架構(gòu)設(shè)計(jì)與實(shí)現(xiàn)
一個(gè)完整的推薦系統(tǒng)不僅是算法模型,更是一個(gè)系統(tǒng)工程。其典型架構(gòu)包括:
- 數(shù)據(jù)層: 負(fù)責(zé)從業(yè)務(wù)數(shù)據(jù)庫(kù)(如MySQL、MongoDB)或日志文件中采集、清洗和存儲(chǔ)用戶行為與商品數(shù)據(jù)。
- 模型層: 核心算法層。使用Python(如Scikit-learn, Surprise, TensorFlow/PyTorch用于深度學(xué)習(xí)模型)實(shí)現(xiàn)和訓(xùn)練協(xié)同過濾模型,并定期更新。
- 服務(wù)層: 提供推薦服務(wù)的API接口。使用Flask或FastAPI等輕量級(jí)Web框架構(gòu)建RESTful API,接收用戶ID等請(qǐng)求,實(shí)時(shí)返回推薦結(jié)果。
- 應(yīng)用層: 前端界面或客戶端,通過調(diào)用服務(wù)層API,將推薦結(jié)果(如“猜你喜歡”、“相關(guān)商品”)展示給終端用戶。
三、 與計(jì)算機(jī)網(wǎng)絡(luò)系統(tǒng)工程服務(wù)的融合
將推薦系統(tǒng)部署到實(shí)際生產(chǎn)環(huán)境,并保證其高性能、高可用與可擴(kuò)展性,離不開堅(jiān)實(shí)的計(jì)算機(jī)網(wǎng)絡(luò)系統(tǒng)工程服務(wù)作為支撐。
- 高性能服務(wù)部署與負(fù)載均衡: 推薦API服務(wù)需要部署在多臺(tái)服務(wù)器上。利用Nginx、HAProxy等工具實(shí)現(xiàn)負(fù)載均衡,將海量的用戶請(qǐng)求分發(fā)到不同的后端Python服務(wù)實(shí)例,避免單點(diǎn)過載,保證低延遲響應(yīng)。
- 分布式計(jì)算與存儲(chǔ): 當(dāng)用戶和商品規(guī)模巨大時(shí),單機(jī)無法存儲(chǔ)和計(jì)算龐大的相似度矩陣。需要引入分布式系統(tǒng),如:
- 分布式存儲(chǔ): 使用HDFS、或云對(duì)象存儲(chǔ)(如AWS S3)存放原始數(shù)據(jù)和模型文件。
- 分布式計(jì)算: 使用Spark(結(jié)合PySpark)或Dask對(duì)協(xié)同過濾中的矩陣運(yùn)算進(jìn)行并行化處理,顯著提升模型訓(xùn)練和相似度計(jì)算速度。
- 實(shí)時(shí)推薦與消息隊(duì)列: 為了捕捉用戶最新興趣,系統(tǒng)需要近乎實(shí)時(shí)地處理用戶行為(點(diǎn)擊、購(gòu)買)。可以引入Kafka、RabbitMQ等消息隊(duì)列。用戶行為日志被實(shí)時(shí)推送至消息隊(duì)列,由下游的流處理程序(如Spark Streaming)消費(fèi)并快速更新用戶特征或模型,實(shí)現(xiàn)動(dòng)態(tài)推薦。
- 微服務(wù)架構(gòu)與容器化: 將推薦系統(tǒng)拆分為數(shù)據(jù)采集、模型訓(xùn)練、在線服務(wù)等獨(dú)立的微服務(wù)。使用Docker容器化每個(gè)服務(wù),并通過Kubernetes進(jìn)行編排管理,實(shí)現(xiàn)服務(wù)的快速部署、彈性伸縮和故障自愈,極大提升了系統(tǒng)的可維護(hù)性和資源利用率。
- 網(wǎng)絡(luò)安全與監(jiān)控: 在系統(tǒng)工程中,必須保障推薦服務(wù)的安全(如API接口的認(rèn)證與防爬蟲)和穩(wěn)定。需實(shí)施HTTPS加密傳輸,配置防火墻規(guī)則,并利用Prometheus、Grafana等工具對(duì)服務(wù)的QPS、響應(yīng)時(shí)間、錯(cuò)誤率進(jìn)行全方位監(jiān)控與告警。
四、
設(shè)計(jì)與實(shí)現(xiàn)一個(gè)基于Python的協(xié)同過濾商品推薦系統(tǒng),是一項(xiàng)涵蓋算法、軟件工程和網(wǎng)絡(luò)系統(tǒng)工程的綜合性任務(wù)。Python憑借其豐富的科學(xué)生態(tài),為快速原型開發(fā)和算法實(shí)現(xiàn)提供了強(qiáng)大支持。而要使系統(tǒng)從實(shí)驗(yàn)室走向生產(chǎn),服務(wù)于百萬級(jí)用戶,則必須依托于現(xiàn)代化的計(jì)算機(jī)網(wǎng)絡(luò)系統(tǒng)工程服務(wù):通過負(fù)載均衡、分布式架構(gòu)、消息隊(duì)列、容器化等技術(shù),構(gòu)建一個(gè)高并發(fā)、低延遲、可擴(kuò)展且穩(wěn)健的推薦服務(wù)平臺(tái)。隨著圖神經(jīng)網(wǎng)絡(luò)、強(qiáng)化學(xué)習(xí)等新技術(shù)的發(fā)展,推薦系統(tǒng)的算法層將更加智能,其對(duì)底層系統(tǒng)工程服務(wù)的性能、彈性和實(shí)時(shí)性要求也將水漲船高,這需要開發(fā)者與系統(tǒng)工程師更緊密地協(xié)作與創(chuàng)新。